Spec #
This is a top-level attribute of the pipeline spec.
{
"pipeline": {...},
"transform": {...},
"spout": {
\\ Optionally, you can combine a spout with a service:
"service": {
"internalPort": int,
"externalPort": int
}
},
...
}
Attributes #
| Attribute | Description |
|---|---|
service | An optional field that is used to specify how to expose the spout as a Kubernetes service. |
| internalPort | Used for the spout’s container. |
| externalPort | Used for the Kubernetes service that exposes the spout. |
Behavior #
- Does not have a PFS input; instead, it consumes data from an outside source.
- Can have a service added to it. See Service.
- Its code runs continuously, waiting for new events.
- The output repo,
pfs/outis not directly accessible. To write into the output repo, you must to use the put file API call via any of the following:pachctl put file- A Pachyderm SDK (for golang or Python )
- Your own API client.
- Pachyderm CLI (PachCTL) is packaged in the base image of your spout as well as your authentication information. As a result, the authentication is seamless when using PachCTL.
Diagram #
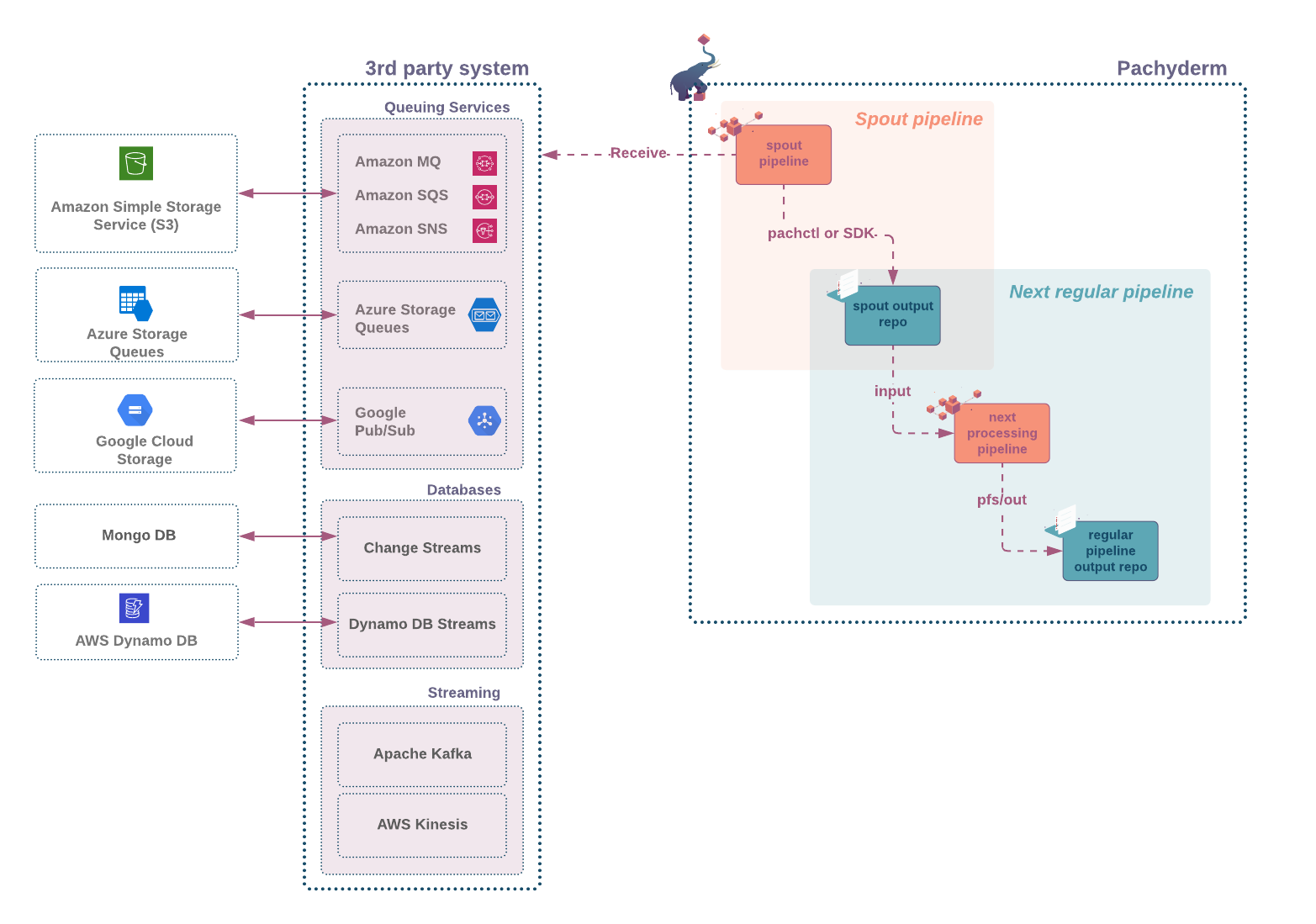
When to Use #
You should use the spout field in a Pachyderm Pipeline Spec when you want to read data from an external source that is not stored in a Pachyderm repository. This can be useful in situations where you need to read data from a service that is not integrated with Pachyderm, such as an external API or a message queue.
Example scenarios:
Data ingestion: If you have an external data source, such as a web service, that you want to read data from and process with Pachyderm, you can use the spout field to read the data into Pachyderm.
Real-time data processing: If you need to process data in real-time and want to continuously read data from an external source, you can use the spout field to read the data into Pachyderm and process it as it arrives.
Data integration: If you have data stored in an external system, such as a message queue or a streaming service, and you want to integrate it with data stored in Pachyderm, you can use the spout field to read the data from the external system and process it in Pachyderm.
Example #
{
"pipeline": {
"name": "my-spout"
},
"spout": {
},
"transform": {
"cmd": [ "go", "run", "./main.go" ],
"image": "myaccount/myimage:0.1",
"env": {
"HOST": "kafkahost",
"TOPIC": "mytopic",
"PORT": "9092"
}
}
}For a first overview of how spouts work, see our spout101 example.